"Bitcoin is a global liquidity capacitor. Post AI singularity, you'll wish you had more capacitance."
Category: DevOps
DevOps specific technologies are grouped together in this dedicated category, but most posts will also qualify for other categories too, e.g. Linux categories.
This is the simplest method of automating ftp operations from PowerShell that I can come up with, having explored MANY incredibly convoluted alternatives.
It is an absolute minimum viable product that can be built upon, consisting of two downloadables that compliment one another and eight commands that probably do everything you need, and do it in a single command.
A link to the wiki for all the cmdlets is given in step 10 below.
Once the WinSCP module is installed, interfacing with an FTP server is as easy as this…CerberusFTP Server displaying the inbound session from PowerShell using WinSCP cmdlets that call WinSCP .NET Assembly winSCPnet.dllDon’t forget to close the ftp session when you’re done….….and the session disappears from Cerberus FTP Server.
0. Download Software
Download matching versions of the Assembly and Cmdlets (5.17.10.0). The most recent version of the Automation .NET Assembly is 5.19.6.0 but you may have issues talking to WinSCP 5.19.6.0 using version 5.17.10.0 Cmdlets such as New-WinSCPSession where it complains about the winscp.exe version not matching the winscpnet.dll version.
Additional commands required for Secure FTP (SSH Hostkey Fingerprint)
The example above was kept as simple as possible to demonstrate the minimum number of steps in order to “get things working”. Now we can build upon those steps and establish an sftp connection to the FTP Server.
Originally developed by Hashicorp, Terraform allows you to define your infrastructure, platform and services using declarative code, i.e. you tell it what scenario you want to get to, and it takes care on the in-between steps in getting you there.
CODE PHASE
E.g., if you wanted to get from a current state of “nothing” to a state of “virtual machine (vm)” and “kubernetes cluster (k8s)” networked together by a “virtual private cloud (vpc)”, then you’d start with an empty terraform file (ascii text file with an extension of .tf) and inside there’d be three main elements, the vm, the k8s cluster and the vpc above. This is called the “Code” phase.
PLAN PHASE
The plan phase compares the current state with the desired state, and forms a plan based on the differences, i.e. we need a VM, we need a K8s cluster and we need a VPC network.
APPLY PHASE
Next, is the Apply phase. Terraform works against the Cloud providers using real API’s, your API token, spin up these resources and output some autogenerated output variables along the way such as the kubernetes dashboard URL etc
PLUGGABLE BY DESIGN
Terraform has a strong open source community and is pluggable by design. There are modules and resources available to connect up to any IAAS cloud provider and automate the deployment of infrastructure there.
Although Terraform is widely considered to support the provisioning of Infrastructure as code from various Infrastructure as a Service (IaaS) cloud providers, it has expanded its use cases into Platform as Service (PaaS) and Software as a Service (SaaS) areas as well.
DEVOPS FIRST
Terraform is a DevOps tool. that is designed and works with the DevOps feedback loop in mind. i.e. If we take our desired scenario above of a VPC, VM and Kubernetes cluster and decide that we want to add a load balancer, then we would add a Load Balancer requirement to the .tf file in the code phase and the plan phase would compare the current state and see that the load balancer is the only change / only new requirement. By controlling the infrastructure using code in the terraform pipeline instead of directly configuring and changing the infrastructure away from it’s original terraform “recipe”, you can avoid “configuration drift”. This is called a “DevOps first” approach and is what gives us the consistency and scalability we want from a cloud based infrastructure, managed using DevOps practices.
INFRASTRUCTURE AS CODE
These days it’s increasingly important to automate your infrastructure as applications can be deployed into production hundreds of times a day. In addition, infrastructure is fleeting and can be provisioned or de-provisioned according to the demand to provide the service that meets customer requirements but also keep control of costs from cloud providers.
IMPERATIVE vs DECLARATIVE APPROACH
An imperative approach allows you to storyboard and define how your infrastructure is provisioned from nothing through to the final state, using a CLI in say, a bash script. This is great for recording how the infrastructure was initially provisioned, and can also make creating similar environments for testing etc but it doesn’t scale well and you are still at risk of others making undocumented changes that send your Dev, Test etc environments out of sync (they should always match) and risks that afore mentioned configuration drift.
So, we use a declarative approach instead, defining the FINAL STATE of the infrastructure using a tool like terraform, and letting the public cloud provider handle the rest. So instead of defining every step, you just define the final state.
IMMUTABLE vs MUTABLE INFRASTRUCTURE
Imagine a scenario where you have your scripts and you run them to get to v1.0 of your infrastructure. You then have a new requirement for a database to be added to the current infrastructure mix of VPC, VM and K8s elements. So, you modify your declarative code, execute it against your existing Dev environment, then assuming you’re happy, make the same change to 100 or 1000 other similar environments, only for it to not work properly, leaving you in a configuration drift state.
To eliminate the risk of this occurring, we can copy and modify our original code that got us to v1.0 and then execute it to create an entirely new and separate v2.0 state. This also ensures that your infrastructure can move to scale. It is expensive while there are v1.0 and v2.0 infrastructures running simultaneously but is considered best practice, and you can always revert to the v1.0 which remains running while v2.0 is deployed.
So, this immutable infrastructure approach, i.e. can not be changed/mutated once deployed, is preferable in order to reduce/eliminate risks with changing mutable infrastructure.
INSTALLING TERRAFORM
I found that terraform was not available via my package repositories, nor from my Software Manager on Linux Mint. So, I downloaded the Linux 64 bit package of the hour from terraform’s website
Unzipping the downloadable reveals a single executable file, terraform.After unzipping terraform, move the executable to /usr/local/bin
I’m using an AWS account, so I’ll need to use the AWS Provider in Terraform.
Next create a .tf file for our project that will initialize the terraform aws provider in the aws region we want and run the terraform init command.
#OpenShot Terraform Project
provider "aws" {
region = "eu-west-2"
}
Our openshot.tf file simply declares the provider (aws) and the region and is read by the terraform init command executed in the same directory.Initialization takes a few seconds.
If you haven’t already got one then you’ll need to set up an account on aws.amazon.com. It uses card payment data but is free for personal use for one year. The setup process is slick as you’d expect from amazon, and you’ll be up and running in just a few minutes.
In your AWS Cloud Management Console, Click Services, EC2.Click Instances, Launch Instance.Click AWS Marketplace and search for openshot
We don’t need to select it since we’re using terraform to build our infrastructure as code, so we can have terraform perform this search. The OpenShot AMI is a terraform DataSource AMI since its an image that already exists – not a Resource AMI i.e. we’re using an existing AMI not creating a new one. Terraform can perform this search for us in our .tf file.
Note that the documentation on terraform’s website uses /d/ or /r/ in the URL for datasources and resources of similarly named elements.
Copy and paste the example code into our openshot.tf file and make a few adjustments to allow access from http and ssh. Note that you should restrict SSH access to your own IP address to prevent exposing your SSH server to the world.
#OpenShot Terraform Project
provider "aws" {
region = "eu-west-2"
}
data "aws_ami" "openshot_ami" {
most_recent = true
owners = ["aws-marketplace"]
filter {
name = "name"
values = ["*OpenShot*"]
}
}
resource "aws_security_group" "openshot_allow_http_ssh" {
name = "openshot_allow_http_ssh"
description = "Allow HTTP and SSH inbound traffic"
ingress {
description = "Inbound HTTP Rule"
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
description = "Inbound SSH Rule"
from_port = 22
to_port = 22
protocol = "tcp"
#NOTE: YOU SHOULD RESTRICT THIS TO YOUR IP ADDRESS!
cidr_blocks = ["0.0.0.0/0"]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
tags = {
Name = "openshot_allow_http_ssh"
}
}
We need to configure a Key Pair for our Amazon EC2 Instance for the SSH to ultimately work. We’ll return to this later when we configure the EC2 instance details in the openshot.tf file we’re constructing.
Configure a SSH Key Pair here.Creating an SSH keypair for our openshot project
Save the openshot-ssh.pem file to your project folder when prompted.
TERRAFORM PLAN
Next, we can test this with the terraform plan command.
terraform plan fails at this stage as we’ve not specified the credentials for our AWS account.
AWS CREDENTIALS
The AWS credentials can be specified as environment variables or in a shared credentials file in your home directory in ~/.aws/credentials more on the options here
The ~/.aws/credentials file can be created by installing the awscli package from your repositories, and running aws configure
Note that you should create an IAM user in your Amazon Management Console, and not create credentials for your aws root user account. I have created an account called matt for example. You’ll receive an email with a 12 digit ID for each IAM user which you’ll need to log in as well as the username and password for that user. The root user just uses an email address and password to log in.
Once you’ve logged in to your AWS Management Console, the credentials are obtained here…
Click on your account user@<12-digit-number>, My Security Credentials
After pasting the Access Key ID in, you’ll be asked for the Secret key next. In the event you don’t have it, you can simply CTRL-C out of aws configure, go back to the aws management console and generate a new one. You’ll only be shown the private key one time, so be sure to copy it, then re-run aws configure and enter the new access key id and secret key. I specified eu-west-2 (London) as my default location and json as my output format.
Note that the credentials are stored in plain text in ~/.aws.credentials
Depending on your situation, you may be able to Deactivate the previous Access Key ID and delete it from AWS Management Console if it’s never going to be used.
TERRAFORM PLAN USING CREDENTIALS FILE
Now if we re-run our terraform plan we see it succeeds.
re-run terraform plan and this time it used the creds found in ~/.aws/credentials
You can see that the Plan outcome at the end is 1 to add, 0 to change, 0 to destroy.
EC2 INSTANCE
Now we’re ready to specify our EC2 Instance and we just need the final section and edit it as shown below based on the data source and resource names specified elsewhere in the terraform file, adding key_name=”openshot-ssh” to refer to our .pem file we created earlier when we generated a SSH key pair for the EC2 Instance on the AWS Management console.
Re-running terraform plan shows our openshot ami resource on our aws ec2 instanceand ends with the message Plan: 2 to add, 0 to change, 0 to destroy.
OUTPUT
Lastly, we can add an output section that outputs the public IP for our OpenShot AMI
output "IP" {
value = "${aws_instance.web.public_ip}"
}
TERRAFORM APPLY
When our terraform plan is ready, we can execute the command terraform apply and terraform will re-execute terraform plan before prompting for input prior to executing the script against the aws cloud provider and building our infrastructure.
terraform apply
Did you like this? Tip cyberfella with Cryptocurrency
In DevOps, you’ll find yourself interacting with or creating files that are either XML, JSON or YAML format, depending on what you’re doing. All these file formats are a way of representing data, and a comparison of the three different file formats representing the same data is shown below.
In DevOps, you’ll find yourself interacting with or creating files that are either XML, JSON or YAML format, depending on what you’re doing. All these file formats are a way of representing data, and a comparison of the three different file formats representing the same data is shown below.
XML, JSON and YAML files representing the same data.
XML, JSON and YAML files representing the same data.
Did you like this? Tip cyberfella with Cryptocurrency
In a single sentence: Kubernetes intends to radically simplify the task of building, deploying and maintaining distributed systems.
Kubernetes or K8s is open-source software, originally created by Google as a way to take on the burden of management of container sprawl for applications/microservices running on multiple containers (vm’s sharing a single kernel on a Linux/UNIX OS) that scale out onto potentially tens or hundreds of individual containers across multiple hosts. Google then handed it to the Cloud Native Computing Foundation.
In kubernetes, there is a master node and multiple worker nodes.
Each worker node manages multiple pods. Pods are just a bunch of containers, clustered together as a working unit.
Application developers design their application based on pods. Once those pods are ready, you tell the master node the pod definitions and how many need to be deployed.
Kubernetes takes the pods, deploys them to the worker nodes. In the event a worker node goes down, kubernetes deploys new pods onto a functioning worker node. The complexity of managing many containers is removed.
It is a large and complex system for automating, deploying, scaling and operating applications running on containers.
MINIKUBE
Rather than create a seperate post on MiniKube, I’ll incorporate it here on my Kubernetes post. MiniKube is a way of learning Kubernetes by running a single node cluster locally on a laptop/desktop machine. The commands required to get it up and running on Linux Mint/Debian are shown below.
#IF YOU USE A COMMAND ALIAS FOR KUBECTL echo 'alias k=kubectl' >>~/.bashrc echo 'complete -F __start_kubectl k' >>~/.bashrc
#START AND OPEN MINIKUBE DASHBOARD minikube dashboard
I had to reboot and enable VTX (virtualisation support) in the BIOS on my HP EliteDesk.
You can check the status of MiniKube and Stop and Start it, using these commands.
#CHECK STATUS minikube status
#STOP MINIKUBE minikube stop
#START MINIKUBE minikube start
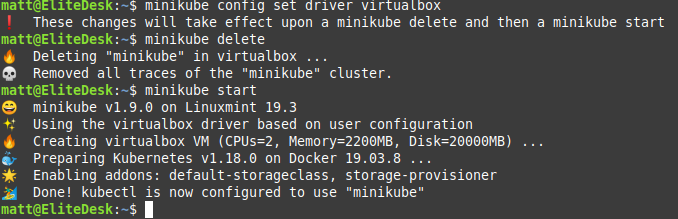
There is an issue with VirtualBox that needs to be resolved.Running minikube config set driver virtualbox, minikube delete and minikube start resolved the issueThe minikube virtual machine can be seen running in the VirtualBox console (virtualbox-qt)
Now that minikube is running, we’re ready to open the console and see our Kubernetes single-node cluster that is running on our local machine.
The minikube dashboard command enables the dashboard and opens the URL in your web browser.The kubernetes dashboard, running on our minikube virtual machine on VirtualBox is displayed in the Brave browser.
BACK TO KUBERNETES…
CONTAINERS AND ORCHESTRATION
To understand kubernetes, we must first understand containers and orchestration. So make sure you’ve read and understood Docker first.
A Kubernetes (K8’s) Cluster was originally developed by Google to manage containers on a very large scale.
In Kubernetes, a Management Cluster (Kubectl) wraps a container called a “Pod” around each Docker container, and clusters Pods into a Replica set which is wrapped into a “Deployment“. A Service wraps around a Deployment and within the Service, a Daemonset controls what runs on each Pod for consistency and a Load Balancer, Cluster IP and Node Port controls the internal networking to simplify communications between Services. An Ingress Controller serves to protect the Service’s External IP from being visible, by controlling inbound URL and API requests and routing them to the Services, Deployments, Pods and Container via the Load Balancer and NodePorts. A Cluster IP facilitates communications between multiple pods via a single, virtual IP.
Using Pod Autoscalers and Cluster Autoscalers, the number of containers that can be deployed and automatically scaled to meet service level requirements is managed using the kubectl command on the Kubectl management cluster.
Rolling updates or a roll back of an image deployed to thousands of pods is done using the kubectl rolling-update command.
kubectl run --replicas=1000 my-web-mywebserver #Runs a 1000 instances of an image in a kubernetes cluster
kubectl scale --replicas=2000 my-web-mywebserver #Scales cluster up to 2000 containers
kubectl rolling-update my-web-server --image=web-server:2 #Performs rolling update to a Deployment of Pods
kubectl rolling-update my-web-server --rollback #Rolls a Deployment Pod image back to previous version
kubectl run hello-minikube #deploy an app to the cluster
kubectl cluster-info #view info about the cluster
kubectl get nodes #view nodes that are part of the cluster
The Master Node contains all the control plane components for the Worker Nodes. It watches over the Worker Nodes and is responsible for the orchestration.
Components in a Kubernetes System: API Server, etcd Key Store, Scheduler, Controller, Container Runtime and Kubelet service
A Kubernetes system consists of the following six components.
API SERVER
This is the front-end component that interacts with management commands, users, other management components (3rd party vendors storage etc).
ETCD
This is the distributed, reliable key value store, where information required to access all the containers is kept and maintained.
SCHEDULER
This is responsible for distributing work to the containers across multiple Nodes. It looks for newly created containers and assigns them to nodes.
CONTROLLER
This is the brain behind orchestration. It is responsible for noticing when endpoints, containers or nodes close down.
CONTAINER RUNTIME
The software used to run containers – in our case Docker but Kubernetes can be used to manage other container technologies too.
KUBELET
The agent that runs on each node in the cluster. It is responsible for making sure the containers are running on the nodes as expected. It listens for instructions from the Controller.
KUBE PROXY SERVICE
The Kube Proxy Service is another service that runs on each Node that makes sure all networking required to facilitate the necessary communication between containers is in place.
KUBERNETES ARCHITECTURE
So to summarise so far, a Kubernetes Architecture consists of the following key components spread across the Master Node and Worker Nodes in the Cluster.
Kubernetes Architecture
KUBEADM
At the beginning of this post, we cover the steps in setting up a KUBECTL single-node kubernetes cluster, with a single worker node. Setting up a multiple node kubernetes cluster manually is a tedious task. KubeAdm is a command line tool that allows us to set up multiple node clusters more easily.
STEPS
You will need multiple virtual machines set up, ready to act as Docker hosts and as the Management and Worker Nodes.
Our existing minikube virtual machine is the only machine currently running in virtualbox – we need more if we are going to run multiple worker nodes.
Note that the minikube VM must be started from the command line using the command
minikube start –driver=virtualbox
not from Oracle VM VirtualBox Manager (virtualbox-qt).
The minikubeVM must be OFF before starting it with the command minikube start –driver=virtualbox
Open the minikube web console in your default browser with the command
minikube dashboard
Open Kubernetes Dashboard in your default browser after starting MiniKube.minikube dashboard opens the above URL in your Browser.The Kubernetes Web Console (click to enlarge)
XML, JSON and YAML
In DevOps, you’ll find yourself interacting with or creating files that are either XML, JSON or YAML format, depending on what you’re doing. All these file formats are a way of representing data, and a comparison of the three different file formats representing the same data is shown below.
XML, JSON and YAML files representing the same data.
PODs with YAML
Did you like this? Tip cyberfella with Cryptocurrency
READ THIS FIRST! On HP workstation equipment, you’ll likely need to enable VTX Extensions in the BIOS to allow for the execution of virtualisation technology. I use a hp EliteDesk 800 G2 Mini and the factory BIOS setting has VTX disabled by default. If in any doubt, check your BIOS now, or you WILL encounter problems later and could waste hours troubleshooting.
When it comes to containers, Docker is the most popular technology out there. So, why do we need containers? How do they differ from VM’s? Very briefly, a VM (as in a VMWare ESXi Virtual Machine) is an entirely self contained installation of an entire operating system that sits on top of a “bare metal hypervisor” layer that sits on top of the physical hardware. Unlike installation of an OS on the physical hardware, the bare metal hypervisor layer allows multiple installations of multiple OSes to co-exist on the same hardware – entirely separate apart from the physical resources they share. There may be cluster of ESXi hosts, managed by a Central vCenter server that allows better distribution of multiple VM’s across multiple physical hosts for the purposes of Distributed Resource Scheduling and High Availability. This is a more efficient use of physical servers, but still quite wasteful on resources and storage since many Windows VM’s for example, would be running the same binaries and storing the same information many times over.
Containers on the other hand are logically separated applications and their dependencies that all reside in an isolated “container” or “zone” or “virtual machine” or “jail” depending on the single instance of an underlying UNIX/Linux based OS. So, they share common components of the underlying OS which is a more efficient use of space and physical resources since only one instance of the operating system is running on the physical machine. This also reduces the overhead on patching and to some extent, monitoring, since in the case of an application hosted on multiple, entirely separate full stack VM’s in a virtual environment, only the parts of the stack with unique/incompatible dependencies are separated into their own container. This means that a container compared to a VM may be very small indeed, and containers are typically restarted in the time it takes to start a daemon or service, compared to the time it takes to boot an entire OS.
So in summary, a container is a more intelligent, more efficient way of implementing the various layers in a full stack application that won’t otherwise co-exist on the same OS due to their individual dependencies for slightly different versions of surrounding binaries and/or libraries.
On VMWare ESXi, there is no Operating System layer (shown in Orange), but VMWare Workstation or Oracle Virtualbox provides similar full OS VM separation within a software hypervisor running as an application in its own right atop an underlying desktop OS such as Windows or Linux. Hence the term bare-metal hypervisor (since the Hypervisor layer shown in Blue runs atop the Server hardware shown in Grey). Docker is similar to a software hypervisor, but rather than store multiple similar full OS/App stacks, it provides separation further up the stack, above the OS layer, such that just the unique requirements of the app/daemon/microservice are hosted in any given container, and nothing more in an effort to become as efficient as it’s possible to be.
REASONS FOR ADOPTING CONTAINERISATION.
In most information technology departments, there’ll be a team of developers who code and build apps using combinations of their own code, database, messaging, web server, programming languages that may each have different dependencies in terms of binaries/libraries and versions of the same binaries/libraries. This is referred to the Matrix from Hell as each developer will be building, knocking down, rebuilding their own development environment that likely runs on their own laptop. There’ll be a development environment too, the intention of which is to mirror that of the production environment although there’s no guarantees of that. There may be other Staging or Pre-Production environments too, again with no guaranteed consistency despite everybody’s best efforts. The problems arise when deploying an app from a Development environment to the Production environment only to find it doesn’t work as intended.
The solution to this problem is to put each component in the application you ultimately want to ship into production/cloud into its own container, i.e.
All the components in the application running on a single Linux OS that has Docker installed can be placed in their own container, i.e…
Once an application component is contained within its own container, all the dependencies that component has (other linux packages and libraries) will also be contained within the same container. So each component has exclusive access to just the packages and libraries it needs, without the potential to interfere with and break adjacent components on the same underlying host operating system.
In order to isolate the dependencies and libraries in this way, a typical Docker container will have its own Processes, Network interfaces and Mount points, just sharing the same underlying kernel.
Two containers with their own processes, network interfaces and mounts share the kernel of the OS that Docker is running on.
Linux containers typically run on LXC, a low level hypervisor that is tricky to set up and maintain, hence Docker was born to provide higher level tools to make the process of setting up containers easier.
Since Docker containers only share the kernel of the underlying OS, have their own processes, network interfaces and mounts, it is possible to run entirely different linux OS’es inside each container, since the only part of the underlying OS that Docker is running on, is the underlying kernel of that OS!
If you want, entirely different linux distributions that are able to run on the same kernel can be run in docker containers! However, since the kernel is very small, this is arguable as wasteful as simply using VMWare ESXi to host individual VM’s each running a different linux distro?!
Since the underlying kernel is the shared component, only OS’s that are capable of running on the same kernel can exist on the same docker host. Windows could not run in the scenario above, and would need to be run on a Windows Server based Docker host instead. This is not a restriction for the VMWare ESXi bare-metal hypervisor of course, where Windows and Linux can co-exist on the same physical host since their kernels are contained within the VM, along with everything else.
HOW IS DOCKER CONTAINERISATION DONE?
The good news is that containers are nothing new. They’ve been about for over a decade and most software vendors make their operating systems, databases, services and tools available in container format via Docker Hub.
Some of the official container images available on Docker Hub.
Once you identify the images you need and you install docker on your host, bringing up an application stack for the component you want, is as easy as running a docker command.
docker run ansible #downloads and runs a container running ansible
docker run mongodb #downloads and runs a container running mongodb
docker run redis #downloads and runs a container running redis
docker run nodejs #downloads and runs a container running node.js
A docker image can be installed mulitple times, for example in a scenario where you want multiple instances of node.js (you’d need a load balancer in front of the docker host(s)) so that in the event of a node.js container going down, docker would re-launch a new instance of that container.
So, the traditional scenario, where a developer puts together a bunch of components and builds an application, then hands it to operations, only for it to not install or run as expected because the platform is different in some way, is eliminated by ensuring all dependencies of each component is contained in its own container, and is thus guaranteed to run. the docker image can subsequently be deployed on any docker host, on prem or in the cloud.
It worked first time!
INSTALLING DOCKER
My everyday desktop machines all run Linux Mint for it’s ease of use and it’s propensity to just work when it comes to my various desktop computing requirements. You’d likely not run it on your servers though, instead choosing Debian or Ubuntu (which Mint is actually based on but not guaranteed to be exactly the same). Your server linux distro choice should be based on support, and by that I mean support for any problems that arise and support in terms of software vendors and in our case, docker image availability.
So, since I’m blogging on this same Mint machine, I’m going to install Docker via the Software Manager for immediacy. I will however cover installation on Ubuntu below.
Quickest and most reliable way of installing a working Docker on Mint, is to use the Software Manager.
sudo docker run hello-world will download the hello-world container, install it and produce the output shown.
always precede your ‘docker’ command with sudo. It needs those root level privileges to communicate with the docker daemon.sudo docker run -it ubuntu bash opens a root shell on container ‘ade951cb999’
From the ubuntu bash container, issuing a few linux commands quickly shows that the container has no reach outside of itself but shares stats returned by the kernel, such as disk space for the /dev/sda2 partition (the docker hosts root partition), cpu, memory and swap utilisation .
The hostname is different, there is only one process running ‘bash‘ (excluding the ps -ef command itself), it can see how much physical disk space is used on the docker host (67% /dev/sda2), it has it’s own set of directories (/home shows as being empty) and the output from top shows only the 1 running process.
Standard linux commands being run inside the ubuntu bash containerThe CPU, Memory and Swap statistics are the same as the Docker host that the container is running on since they share the same kernel. /etc/issue says Ubuntu despite the Docker host being Linux MintThe Docker host running Linux Mint.cat /etc/*release* reveals more information about the operating system running in the container.
To display the version of docker thats been installed, use sudo docker version
sudo docker version
DOCKER IMAGES AND COMMANDS
Remember, you probably need to precede docker commands with sudo.
Here are some initial commands before I stop to make an important point…
#DOCKER COMMANDS
docker run nginx #checks for a local copy of the nginx container image, if there isn't one, it'll go out to docker hub
# and download it from there. For each subsequent command, it'll use the local copy.
docker ps #lists all running containers
docker ps -a #lists all containers present, running or otherwise
docker start <container-id> or <container-name> #(re)start a non-running container
docker stop <container-id> or <container-name> #stop a running container
docker rm <container-id> or <container-name> #remove container
docker images #shows all docker images downloaded from docker hub on the local system
docker rmi nginx #removes the docker image from the system (make sure non are running)
docker pull ubuntu #pulls ubuntu image to local system but dont run it until docker run command is issued
Containers are only running while the command executed inside them is running. Once the process stops, the container stops running. This is an important distinction from VM’s that stay running and consuming system resources, irrespective. Note also the final column, a randomly assigned “name” for the container.
An important distinction between containers and VM’s is that whereas a VM stays running all the time, a container is only running while the command inside it is running. Once the process for the command completes, the container is shutdown, thus handing back any and all resources to the docker host.
Taking the 1st, 2nd and 3rd columns from the sudo docker ps -a command above for closer inspection, you can see that there is a container ID, the docker image, and the command run within that docker image, e.g.
Earlier we executed the command sudo docker run ubuntu bash and the docker host checked for a local copy of the ubuntu image, didn’t find one, so downloaded one from docker hub. It then started the container, and ran the bash command within that container, and thus we were left as a running bash command prompt on our container running ubuntu. As soon as we typed exit, the bash terminal closed, and since there were no running processes remaining on that container, the container was subsequently shut down.
Another container, docker/whalesay was also downloaded and ran the command cowsay Hello-World! before exiting and unlike ubuntu bash dropped us back at our own prompt on the docker host. This is because once the cowsay Hello-World! command had executed, there was no further need for the container, so it was shut down by the docker host.
docker exec mystifying_hofstadter cat /etc/hosts #execute a command on an existing container
docker start <container-id> or <container-name> #starts an existing non-running container
docker stop <container-id> or <container-name> #stops a running container that's been STARTed
So, docker run <image-name> <command> will get a docker image, start it and execute a command within it, downloading the image from docker hub if required. But once the image is stored locally and that container exists on our docker host system, albeit in an exited state, what if we want to run the command again. Well, docker run <image-name> <command> will create another duplicate container and execute the command in that. We want to execute the same command in the existing container. For that we use the docker start command followed by the docker exec command and optionally finish up with the docker stop command e.g.
Before using docker exec to execute a command on an existing container, you’ll need to docker start it first.
DETACH and ATTACH (background and foreground)
If you’re running a container that produces some kind of output to the foreground but you want to run it and return to the prompt instead, like backgrounding a linux command, you can docker run -d <container> to run it in detached mode. To bring that running container to the foreground, you can docker attach <container>. Where <container> is the id or name of the container.
docker run -d kodekloud/simple-webapp #runs a container in the background if it would otherwise steal foreground docker run -a <container-id> #bring detached container (running in the background) to the foreground
If you have a docker image like redis, that when run with docker run, will stay running interactively in the foreground, there is no way to background it (detach it) without hitting CTRL-C to kill the process, then re-run it with docker run -d so that it runs in detached mode. However, if you run your containers with docker run -it then you can use the key sequence CTRL-P CTRL-Q to detach it without killing it first. Reattach using the docker attach <container> command. According to the docker run –help page, -i runs in in interactive mode and -t allocates a pseudo tty (terminal) to the running container.
DOCKER COMMANDS AND HELP SYSTEM
Docker has a very nicely thought out help system. Simply type docker and all the management commands and docker commands are listed along with descriptions. Type docker <command> –help and you’ll see more information on that particular command.
docker commands. Use docker <command> –help to dig deeper.
RUN TAG
If we run a container e.g. redis with docker run redis, we can see in the output the the version of redis is Redis version=5.0.8
The version TAG is Redis version=5.0.8 in our redis container.
If we wanted to run a different version of redis, say version 4.0, then we can do so by specifying the TAG, separated by a colon e.g. docker run redis:4.0
Run a different version of the redis container by specifying the TAG in the the docker run redis:4.0 command
In fact, if you specify no TAG, then what you’re actually doing is specifying the :latest tag, which is the default if no tag is specified. To see all the Tags supported by the container, go to docker hub, search for the container and you’ll see the View Available Tags link underneath the command.
RUN -STDIN
Already mentioned above, if you have a simple shell script that prompts for user input, then produces an output, e.g.
#!/bin/bash echo "What is your name?" read varname echo "Hello $varname. It's nice to meet you." exit
hello.sh needs to prompt the user for input before producing an output.
If this simple program were containerised with docker, when run, it needs to prompt the user for input before it can produce an output. So, the command needed to run this container, would be docker run -i -t <image>. The i runs the container in interactive mode so you can enter stdin, and the t allocates a pseudo terminal so you get to see the stdout.
PORT MAPPING
Before talking about port mapping, I’ll first cover how to see the internal ip address assigned to the container and the port the container is listening on. The output of docker ps will display a PORTS column, showing what port the container is listening on, then use docker inspect <container-name> to see the IP Address.
display the port using docker ps and use docker inspect to display the internal ip address.
The internal IP address is not visible outside of the docker host. In order for users to connect to the port on the container, they must first connect to a port on the docker host itself, that is then mapped to the port on the container i.e.
Here we see port 80 on the docker host is mapped to port 5000 on the container running a web app.
To map a local port on the docker host to a listening port on the container, we use the docker run -p 80:5000<image-name> command. The -p stands for publish and creates a firewall rule allowing the flow of traffic through the specified ports. By default a container doesn’t publish any of its ports.
Users can connect to the IP and Port on the Docker host, and be tunnelled through to the container.
VOLUME MAPPING AND PERSISTENT DATA
If you’re running a container that stores data, any changes that occur are written inside that container. e.g. a mysql container will store it’s tablespace files in /var/lib/mysql inside the container.
A MySQL database will write data to it’s internal file system. But how does that work?
docker run -v /opt/datadir:/var/lib/mysql mysql mounts the directory /opt/datadir on the docker host into /var/lib/mysql on the mysql container. Any data that is subsequently written to /va/rlib/mysql by the mysql container, will land on /opt/datadir on the docker host, and as such will be retained in the event that the mysql container is destroyed by docker rm mysql.
CONTAINER INFORMATION
Already mentioned before, the docker inspect command returns many details about the container in JSON format. ID, Name, Path, Status, IP Address and many other details.
LOGS AND STDOUT
So, you can run the docker run -it redis command and see the standard output, but if you have an existing container that you start with docker start <container-name> and then attach to it using docker attach <container-name> you won’t see any stdout being sent to the screen. This is because unlike running it interactively with an assigned tty, simply starting the container and attaching to it, will not assign a tty. In order to view the stdout on the container, use the docker logs <container-name> and you’ll see the same output that you would if you used the docker run -it redis command. Obviously, using docker run redis would create a new container using the redis image, not start an existing redis container.
Starting and attaching to a container that produces stdout will not display the stdoutUsing the docker logs <container-name> command to view the stdout on that container.
ENVIRONMENT VARIABLES
Consider the following python code web-page.py to create a web server that serves a web page with a defined background colour and a message. If the python program has been packed up into a docker image called my-web-page, then you’d run it using the docker run my-web-page command, connect to it from the web browser on the docker host on port 8080 to view the page.
import os
from flask import Flask
app = Flask (__name__)
color = "red"
@app.route("/")
def main():
print(color)
return render_template('hello.html', color=color)
if __name__ == "__main__":
app.run(host="0.0.0.0", port="8080")
The python program has a variable color=red within it but you want to be able to pass in values for that variable from the docker host when you run the container. To do this, you can move the variable outside of the python code by replacing the line of color=red with color =os.environ.get(‘APP_COLOR’)
import os
from flask import Flask
app = Flask (__name__)
color = os.environ.get('APP_COLOR')
@app.route("/")
def main():
print(color)
return render_template('hello.html', color=color)
if __name__ == "__main__":
app.run(host="0.0.0.0", port="8080")
On the docker host, you can create and export a variable export APP_COLOR=blue; python web-page.py and refresh the page and the colour will change since it’s value is being read from an external variable on the docker host.
To run a docker image and pass in a variable, you can use the command
docker run -e APP_COLOR=orange my-web-page
to pass the variable APP_COLOR-orange into the container image my-web-page before the container is started.
To find the environment variable set on a container, you can use the docker inspect <container-name> command, and in the JSON file, under the “config”: { section, “env”: { subsection, you’ll see “APP_COLOR=blue” variable, along with some other variables too.
docker inspect will show the variables passed in from the docker host
CREATING A DOCKER IMAGE
So, you now have a good idea on how to interact with docker images and docker containers running on your linux system. We’ve even seen some code that can be containerised but we’ve not elaborated on how you get from a python program or shell script to a docker container image. Lets cover that important topic next.
Firstly, lets ask “Why would you want to dockerize a program?”. There are two answers to that question. The first is that you cannot find what you want on docker hub already, so you want to make it yourself. The second is that you have a program on your development laptop/environment and want to containerise it for ease of shipping to operations teams or docker hub and deployment on production infrastructure.
So, taking the above example of a web server and web page python script called web-page.py that uses the python flask module. If i were to build a system to serve that page, I’d follow the following steps.
Install the Ubuntu OS
Perform a full update of all packages using apt-get update && apt-get dist-upgrade
Install python3.x and any dependencies using apt-get install python3
Install python3.x script module dependencies using the python pip package manager
Create/Copy the python source code into /opt directory
Run the web server using the flask command.
DOCKER FILE
A docker file is basically the sequence of commands required to perform the sequence of steps listed above. It is written in an INSTRUCTION, Argument format. Everything on the left in CAPS is an Instruction, and everything that follows it is an argument.
It looks like this…
#Dockerfile for cyberfella/my-web-page
FROM Ubuntu
RUN apt-get update
RUN apt-get install python
RUN pip install flask
RUN pip install flask-mysql
COPY . /opt/source-code
ENTRYPOINT FLASK_APP=/opt/source-code/web-server.py flask run
Docker has a “layered architecture”. This means that when you run docker build (shown below), it builds a docker image that contains only the parts of the application added by each line in the Dockerfile. Think of the Dockerfile as the recipe, the docker build command as the chef and the docker image as the dish (and I suppose docker hub as the restaurant if we take this food analogy all the way to its logical conclusion!).
The first line contains a FROM instruction. This specifies the base OS or another docker image.
To build the docker image, use dockerbuild Dockerfile -t cyberfella/my-web-page command. This will create a local docker image called my-web-page.
Note that if your Dockerfile lives in a directory called MyApp, then you need to specify the folder that contains the Dockerfile in it in the docker build command, e.g. sudo docker build MyApp -t cyberfella/my-web-page
docker build adds each layer based on the actions of each instruction in the Dockerfile, to create the Docker image. Each layer only stores the changes from the previous layer, which is reflected in the size of the image file.docker build output clearly shows the activity based off each line in the Dockerfile
If the docker build process fails during the processing of one of the layers, then once you have fixed the issue, the build process will start again at the failed layer since all previous layers are stored in the docker hosts cache. This means docker is very quick to rebuild an image, compared to the first time the image is built.
Re-running docker build will use the contents of the cache for layers that were previously successfully built. This makes the docker build process faster over time as small changes are all that are implemented with each subsequent run of docker build.
To push the image to Docker Hub, use the command docker push cyberfella/my-web-page
If docker push fails, you’ve probably not used docker login to log in to your repository on docker hub!
Note that cyberfella is my Docker Hub login name. You will need to register on Docker Hub first so that there’s a repository to push to and you’ll need to log into your repository from the docker host using the docker login command. You can also link your Docker Hub repository with your GitHub repository and automate new Docker image builds when updated code is pushed to GitHub!
You can see the size of each layer in the image by using the command docker history<image-name>
docker history <image-name> displays the amount of data being added to the image in each layer of the docker build process
COMMANDS ARGUMENTS AND ENTRYPOINTS
If you recall the last Instruction line in the Dockerfile was CMD and the Argument that follows it is the name of the command or daemon that you want your container to execute. These arguments can take the form of the command you’d ordinarily type in a Shell, or can be specified in JSON format, e.g.
The sleep 5 command can be specified as sleep 5, or as [“sleep”, “5”] in JSON format, whereby the first element is the executable and the second element the argument passed into the executable.Building a Dockerfile that consists of two Instruction and Argument lines, FROM ubuntu \ CMD [“sleep”, “5”] took around a second. This is because the cache already contained the build artifacts from a prior successful FROM ubuntu instruction.
When we run the cyberfella/ubuntusleeper container, it will sleep for 5 seconds and then exit, just as if we ran the command sleep 5 from our Ubuntu terminal. Remember, if we wanted to run our ubuntusleeper container for 10 seconds, we don’t need to rebuild it, we can optionally pass in the amount of time we want as a parameter, e.g. sudo docker run cyberfella/ubuntusleeper sleep 10 passing in the executable and argument as parameters that will override the default parameters set in the Dockerfile when the image was built.
This still looks a little untidy. the imagename ubuntusleeper implies that the container will sleep, so we don’t want to have to pass in sleep 10 as parameters going forward. We’d prefer to just have to enter sudo docker run cyberfella/ubuntusleeper 10. This is where the ENTRYPOINT Instruction comes in. If we add an Instruction to our Dockerfile ENTRYPOINT [“sleep”] then any argument passed in, will be passed into that executable by default.
After appending ENTRYPOINT [“sleep”] the re-build of the docker image and pushing it to docker hub takes mere seconds.
This works great until the image is run without any parameters, at which point it’ll error with a missing operand error. To overcome this, edit the Dockerfile to contain the ENTRYPOINT instruction first and the CMD instruction after, but remove the sleep command from the CMD instruction since it will default to using it from the ENTRYPOINT instruction.
FROM ubuntu ENTRYPOINT [“sleep”] CMD [“5”] is all you need in your Dockerfile in order to pass in no parameters or just the parameter for the sleep duration in seconds. This only works for Dockerfiles written in JSON format.
Lastly, if you wanted to override the ENTRYPOINT parameter when running the docker image and replace sleep with, say, sleep2.0 then this can be done by specifying the new entrypoint on the docker run command, e.g. sudo docker run –entrypoint sleep2.0 cyberfella/ubuntusleep 5
DOCKER NETWORKING
When you install Docker, it creates three networks, bridge, None and host.
Bridge is the default network a container gets attached to. To specify a different network for the container to get attached to, use the –network= parameter in the docker run command, e.g sudo docker run –network=host cyberfella/ubuntusleep
The bridge network is the default network that containers get attached to on the docker host. They can all talk to one another, but there is no connectivity to the outside world (see PORT MAPPING above in this post for how to map ports on the docker host to ports on the containers)
The host network removes any network isolation from the docker host. This means that the IP address is the same as the docker host. This also means that you can’t host similar containers serving over the same port and that you cannot ship containers to other docker hosts so easily, without causing some disruption.
The none network, simply put, means the container is not connected to any network.
USER DEFINED NETWORKS
It is possible to create more than the default bridge network, so that groups of containers can talk to one another, but you can introduce some isolation between different groups of containers on the same docker host.
User defined networks allow only certain containers to be able to communicate with one another on a given docker host.
The command to set up this extra bridge network on the docker host, would be…
To list all networks on the docker host, use the docker network ls command.
Remember the docker inspect command can be used to view IP addresses assigned to docker containers? To view the network settings for a specific container, use the command sudo docker inspect blissful_wozniak
Note that a docker container is only connected to the network and has an IP address when it is running. There is no IP address information for non-running containers in an existed state.
On the left, the network information for a non-running container, compared to a running container on the right.
EMBEDDED DNS
Containers can contact one another using their names. For example, If you have a MySQL Server and a Web Server that need to communicate with one another, it is not ideal to configure IP Addresses in a mysql.connect(), since there is no guarantee that a container will get the same IP address from the docker host each time it is started.
The docker host creates a separate namespace for each container and uses virtual ethernet pairs to connect the namespaces together.
containers should be configured to communicate using their names.
DOCKER STORAGE
So, where does the docker host store all it’s files? In /var/lib/docker
The docker host’s filesystem and containers directories.Recall how the build process is a layered architecture, where each build stores only the changes made within each layer.
With each subsequent build of new containers that share the same base layers as existing containers, only the differences are stored.
If we turn the build process upside down so we’re starting at the bottom layer with a base image from docker hub, then working our way up to a newly built container, we will call these layers the Image Layers. When we run that container with the docker run command, docker host creates a new Container Layer on top where it stores the changes occurring on that running container. This container layer exists while the container is running and is destroyed once the container exits. There is no persistent storage by default.
The container layer only exists while the container is running. Then it is destroyed.
COPY ON WRITE MECHANISM
The difference between our Image Layers and Container Layers on a running container, is that the Image Layers are Read Only or “Baked in”. Only the Container Layer is Read/Write. If we attempt to modify the code of the script specified in our Entrypoint, then we are not modifying the code in the Image Layer. We are taking a copy of that code from the Image Layer/Entrypoint and modifying that copy.
Remember, when the container exits, it is destroyed and there is no persistent storage by default. Running a container and modifying its entrypoint code will not change the underlying container image contents.
This is known as the Copy on Write mechanism i.e at the point that you write a change, a copy is made and changes written to that copy.
At the point at which the container exits, the image layers and the container layer and is data are destroyed until a container is run again from the built image consisting only of immutable image layers.
If we have a container that we want to write some data that we want to be persistent, i.e. survive after the container is destroyed, then we need to create a volume outside of the container and mount it inside the container.
VOLUME MOUNTING
Create a volume called data_volume using the docker volume create command data_volume command on the docker host that will run your container.
A folder called data_volume will then be created in the /var/lib/docker/volumes/ directory on the docker host.
To mount the volume in your container, run the container with the command docker run -v data_volume :/var/lib/mysql mysql(where mysql is the image name in this example and /var/lib/mysql is the directory on the container that you wish to be the mount point for the data_volume volume on the docker host).
If you run a container and specify a non-existent volume, e.g. docker run -v data_volume2:/var/lib/data ubuntu then rather than error, it will actually create a volume called data_volume2 and mount it into the specified directory, in our case /va/rlib/data on a container running using the ubuntu image.
MOUNTING EXTERNAL STORAGE (BIND MOUNTING)
If the docker host has mounted some external storage, into lets say /data/mysql on the docker host, and we wish to mount that on our running container, then we use the docker run -v /data/mysql:/var/lib/mysql mysql command to accomplish this, specifying the mount point on the docker host rather than the volume, followed by the mount point on the container and the image name just as before.
The -v switch is the old method. The newer standard is to use –mount instead, an example of bind mounting using the newer –mount way, is shown below
docker run --mount type=bind,source=/var/san-mysqldata-vol01,target=/var/lib/mysql mysql
The docker storage drivers control the presentation of one type of filesystem to the docker container that mounts it. Commonly supported file system types are aufs, zfs, btrfs, device mapper, overlay, overlay2
DOCKER COMPOSE
We’ve covered how to run docker containers using the docker run command, and how we can run multiple containers built from different images, but if we want to run an application built from multiple components/containers, a better way to do that is to use “docker compose”, specifying the requirements in a YAML file.
The individual docker run commands shown above, the single docker compose yaml file shown below
A docker-compose.yml file for your app stack might look like this,
The stack is then brought up with the command docker compose up
Lets look at a more comprehensive example, often used to demonstrate docker. Consider the following voting application architecture.
The architecture/data flow for a simple voting application, where the voting app is a python program and the votes are stored in a postgresql database and ultimately the results are displayed in a node.js web page
Imagine if we were going to run this manually, using docker run commands and the images were already built/available on docker hub, we’d start each container like this…
docker run -d --name=vote -p 5000:80 voting-app
docker run -d --name=redis redis
docker run -d --name=worker worker
docker run -d --name=db postgres:9.4 db
docker run -d --name=result -p 5001:80 result-app
But our application does not work because despite running all these required detached containers and port-forwards for our app, they are not linked together. In fact, on our docker host, we may have multiple instances of redis containers running. The console will display errors akin to “waiting for host redis” or “waiting for db” etc.
So how do we associate the containers for our app with one another, amongst other containers potentially running on our docker host?
Going back to our architecture, the python voting app is dependent on the redis service, but the voting app container cannot resolve a container with the name redis, so in our command to start the voting app container, we’d use a –link option to make the voting app container aware of the container named redis with the hostname of redis. This is why we used the –name=redis redis option in our docker run commands above.
# Use --link <container-name>:<host-name> option
docker run -d --name=vote -p 5000:80 --link redis:redis voting-app
This actually creates an entry in the hosts file on the voting app container for the redis host. So what other links would we need here?
Well our result-app container needs to know of the db container in order to display the results…
docker run -d --name=vote -p 5000:80 --link redis:redis voting-app # --link <container-name>:<host-name>
docker run -d --name=redis redis
docker run -d --name=worker --link db:db ---link redis:redis worker
docker run -d --name=db postgres:9.4 db
docker run -d --name=result -p 5001:80 --link db:db result-app
Our .NET worker container needs to know of the db and redis containers…
docker run -d --name=vote -p 5000:80 --link redis:redis voting-app # --link <container-name>:<host-name>
docker run -d --name=redis redis
docker run -d --name=worker --link db:db ---link redis:redis worker
docker run -d --name=db postgres:9.4 db
docker run -d --name=result -p 5001:80 --link db:db result-app
Our redis and db containers don’t need to make contact with anything since all communications to these are inbound in our app.
docker run -d --name=vote -p 5000:80 --link redis:redis voting-app # --link <container-name>:<host-name>
docker run -d --name=redis redis
docker run -d --name=worker --link db:db ---link redis:redis worker
docker run -d --name=db postgres:9.4 db
docker run -d --name=result -p 5001:80 --link db:db result-app
With our docker run commands ready, we can now think about putting together our docker-compose.yml file for our app.
The docker-compose-yml file equivalent for our application stack (above and below)
#DOCKER COMPOSE EQUIVALENT TO DOCKER RUN COMMANDS
redis:
image: redis
db:
image: postgres:9.4
vote:
image: voting-app
ports:
- 5000:80
links:
- redis
result:
image: result-app
ports:
- 5001:80
links:
- db
worker:
image: worker
links:
- redis
- db
Underneath each section for each of our containers, we’ve specified the image we wish to use. Two of our containers are just images available from docker hub but the other three are using our own in-house application code. Instead of referencing the built image of these in-house containers, the code can be referenced in our docker-compose.yml file instead. The docker host will build our container using the Dockerfile and surrounding code in the directory that contains all the elements required to build our container image using the lines build: ./vote and build: ./result and build: ./worker instead of image: voting-app etc. i.e.
substitute build: lines in place of image: lines to point docker compose right at the code for the containers.
There are currently 3 different formats of docker-compose files since docker compose has evolved over time. Lets look at the differences between v1.0 and v2.0
Version 1 and Version 2 format for the docker-compose.yml file
docker-compose version 1 connects all containers to the default bridged network, whereas docker-compose version 2 creates a new, separate dedicated bridge network on the docker host, and connects each container to that – presumably for better isolation and better security.
version: 2 must be specified at the top of the docker-compose.yml file and all version 1 elements move under a section called services:) Because of this isolated bridge network, links are created automatically between the containers, so the link: lines are also no longer required.
Version 2 also supports a depends on: feature, to control the start up order of containers.
Version 3 looks like Version 2 but has version: 3 at the top (obviously). It also is used by Docker Swarm and Docker Stacks, which we will come on to later.
Going back to Docker Compose Networks, what if we wanted to separate our traffic on the front end App and Results servers from our back end Redis, Worker and DB?
We’d need to create a network for the voting and results containers to connect to, i.e.
Front-end network to connect users to voting app and results app
and all components to a separate back end network, i.e.
Back-end network to connect all containers in our app stack
Our version 2 docker-compose.yml file would need to have a map of networks added, i.e.
The docker registry is the place where the docker images come from. We run a docker container with a command like docker run nginx and then magically, if the image doesn’t already exist, docker host goes and downloads the latest nginx image from the docker hub repository nginx/nginx:latest i.e. if only nginx is specified, then docker assumes that the docker hub user name is nginx and the repository name is nginx and if no tag is specified, it’ll assume the :latest tag and download the latest version of the image that exists in the nginx/nginx respository. In summary, the first nginx is the docker hub user account and the second nginx is the repository name where the image lives. If there are multiple images for that container in the repository, then they’ll have a tag to denote the version or that they are the latest version of the container image. Since we did not specify the docker registry, it was assumed that we meant the docker.io registry, i.e. docker.io/nginx/nginx:latest
There are other registries too, where docker images can be found, such as Googles Kubernetes registry, gcr.io/kubernetes-e2e-test-images/dnsutils for performing end-to-end tests on the cluster for example. These are publicly accessible images that anybody can download.
PRIVATE REGISTRY
If you have images that should not be made available publicly, you can create a private registry in house. Alternatively AWS, Azure or GCP provide a private registry when you create an account on their cloud platform.
To obtain a container image from a private registry, you must first log into the private registry with your credentials using the docker login command
docker login private-registry-name.io
The first time you log into docker.io or any other registry, you’ll be prompted for username and password credentials, which are then stored with root perms in /home/you/.docker/config.json. Despite the warning, I found the password to be stored in the form of a hash of my actual plain text password in this file.
Each time you login into the registry, it uses stored credentials for the authentication.
The credentials are stored as a hash in the /home/you/.docker/config.json file that is secured with permissions that only permit the root user on your docker host, access.
You need to log into a registry before you can push or pull an image.
When you use a Cloud account provider like AWS or Azure, a private registry is created when you open an account. If you wanted to deploy an on-premise private docker registry however, you could do so using the command docker run -d -p 5000:5000 –name registry registry:2
To create a private repo, tag an image prior to pushing it to it, or to pull it from a local or network private repo, use the commands shown below.
Private Repository related command examples
docker login private-registry.io #logs in to private image registry (prompts fro creds)
docker run -d -p 5000:5000 --name registry registry:2 #creates on-premise private docker registry
docker image tag my-image localhost:5000/my-image #Tag the container image prior to pushing to local private repo
docker push localhost:5000/my-image #push image to local private repo
docker pull localhost:5000/my-image #pull image from local private repo
docker pull 192.168.56.100:5000/my-image #pull from private repo on network
DOCKER ENGINE
When you install docker engine on a host, you’re actually installing three components, the Docker Command Line Interface, the REST Application Programming Interface and the Docker Daemon.
The Docker CLI talks to the Docker Daemon via the REST API
An important point is that the Docker CLI need not reside on the docker host in order to communicate with the Docker Daemon. If using a docker CLI on a laptop to talk to a remote Docker Host for example, use the following command…
docker -H=remote-docker-engine:2375 forms the first part of a command executed on a remote docker host
docker -H=remote-docker-engine:2375 #first part of a command to execute on a remote docker host
docker -H=10.123.2.1:2375 run nginx #runs nginx on a remote docker host
CONTAINERIZATION
How does Docker work under the hood.
Docker utilises namespaces to isolate workspace. Process ID, Network, Timeslicing, InterProcess communication and Mount are created in their own namespace thereby providing isolation within containers
NAMESPACE PID
When a linux system boots up, the root process PID 1 is the first process to start, followed by other services with incremental, unique process ID’s. Because of this, each container must think it is a unique system, originating from a root process with a PID of 1.
Each container thinks that it is it’s own system originating from a root PID of 1, just like any other Linux system.
Since the processes are all running on the same host system and Process ID’s must be unique, we cannot have more than one process ID of 1, 2,3 etc. This is where process namespaces come into play. If we were to look, we’d see the same process running on both the container and the docker host, but with different PID’s.
Notice how the there is one container running a /bin/bash process. On the docker host, only one of the /bin/bash processes is running as the root user. When I stop the container, that is the process that dies.
By default, there is no restriction on how many system resources a container can use.
There is a way to restrict how much CPU and Memory a container can use. Docker uses cgroups to do this. To limit the amount of CPU and/or Memory a container uses, use the following commands in docker run.
docker run --cpus=.5 ubuntu #ensures ubuntu image doesnt use more than 50% CPU on the docker host
docker run --memory=100m ubuntu #limits the amount of ram to 100M
Remember, Docker containers use the underlying kernel so for linux containers, you need to run docker on a linux host. Thats not to say the docker host can’t be a VM running on a hypervisor on a Windows physical host. If you want to play around with Docker, but only have access to a WIndows machine, then you can install Oracle Virtualbox on Windows and create a Linux Ubuntu, Debian or CentOS VM. Then, install docker on the Linux VM and try out all the different commands for yourself. Docker provides the Docker Toolbox which contains all the pieces of software you might want in order to try it out, but instead of having to download the software from many different places, Docker put it all together in one place for your convenience. This is or older versions of Windows that don’t meet the new Docker Desktop Standard.
The latest option for Windows 10 Enterprise or Professional or Windows Server 2016, is Docker Desktop for Windows, which removes the need for Oracle Virtualbox and uses Windows Hyper-V virtualisation instead.
Docker Desktop uses Hyper-V and the default option is Linux containers, however, Docker has announced that you can now package Windows containers for use on a Windows host, using Docker Desktop.
To use Windows containers, you must switch to Windows Containers mode in Docker Desktop in the menu.
Unlike Linux, in Windows there are two types of Windows Container. The first is Windows Server. The second is Hyper-V isolation, whereby a highly optimised VM guarantees total kernel isolation from the WIndows host.
Windows Server containers and Hyper-V Isolation Containers. The latter guarantees Kernel isolation from the host.
Orchestration solutions such as Docker Swarm and Kubernetes (Google K8’s) allow for the deployment and scaling of many docker hosts and many docker containers across those cluster with advanced networking and sharing of cluster resources and storage between them. Docker Swarm is easy to set up but lacks some of the more advanced features now available on other solutions like Mesos and Kubernetes. Kubernetes is one of the highest ranked projects on GitHub.
DOCKER SWARM
Docker Swarm is a cluster that facilitates the deployment of docker hosts and high availability and load balancing for docker containers.
A Docker Swarm Cluster requires one host to be the designated Swarm Manager, and other Docker Hosts are the Workers.
To create a Docker Swarm Cluster, run the following commands on your designated Manager and Workers respectively. The docker swarm init command will generate a token code to use on the workers in that cluster.
docker swarm init --advertise-addr 192.168.1.12 #Initialize Swarm Manager
docker swarm join --token SWMTKN-1-<token-code> <token-mgr-ip>:2377docker swarm join-token manager #Add a amanger to a Swarm
docker service create --replicas=3 <image-name> #Deploy a docker image to a Swarm
Just as with the docker run command, the docker service command supports many of the same commands e.g.
docker service create --replicas=3 --network frontend <image> #Deploy a docker image to a Swarm, connected to front end network
docker service create --replicas=3 -p 8080:80 mywebserver #Deploy mywebserver image with port forwarder
KUBERNETES
There is a more in-depth review of Kubernetes here, where the journey into the topic of containerisation continues.
Did you like this? Tip cyberfella with Cryptocurrency
Python is a simple, easy to learn programming language that bears some resemblance to shell script. It has gained popularity very quickly due to its shallow learning curve. It is supported on all operating systems. https://www.python.org/
INSTALLATION
Installers for all operating systems are available here and on linux it tends to be installed by default in most distributions. This is quickly and easily checked by using the python3 -V command.
You may find that the version installed in your distribution lags slightly behind the very latest available from python.org. If you want to install the very latest version, then you can either download the source code and compile it, or add the repository and install it using your package management system. Check the version you want isn’t already included in your package management system first using apt-cache search python3.8
INSTALLATION VIA SOURCE CODE (debian based distributions)
Ensure the pre-requisites are installed first from the distro’s default repo’s.
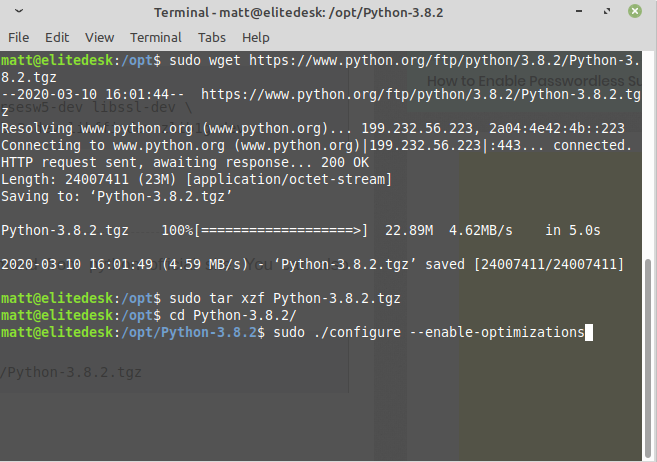
Download the source code from here or use wget and unzip using tar -zxvf Python-3.8.2.tgz
Download the python source code from the command line using sudo wget https://www.python.org/ftp/python/3.8.2/Python-3.8.2.tgz
Extract the archive using tar xzf Python-3.8.2.tgz cd into Python-3.8.2 directory sudo ./configure –enable-optimizations to create makefile sudo make altinstall to install python without overwriting the version already installed in /usr/bin/python by your distroCheck python version with the python3.8 -V command
EXECUTING A PYTHON SCRIPT
Before getting into coding in python, I’ll put this section in here just to satisfy your curiosity about how you actually execute a python script, since python ain’t shell script…
The simplest of all python scripts? The simple “hello world” script hello-world.pyAttempting to execute a python script like you would a shell script doesn’t end well. Python ain’t Shell after all.
The hint was in the use of the python3.8 -V command previously in order to check the version of python i.e. to execute your python script using python 3.8.2, you could use the command python3.8 hello-world.py
PYTHON PROGRAMMING
COMMENTS
Comment code or your own comments throughout your python code for readability by placing a # at the front of the line. The python interpreter will ignore any lines beginning with a hash symbol. Alternatively, use a triple quote, e.g. ”’ but hashes are the official method of commenting a line of code/notes.
WORKING WITH STRINGS
hello world.
print(“hello world”) -prints the output hello world to the screen
country_name = “England” -create a variable country_name and assign string value of England
number_of_years = 2020 -create a variable number_of_years and assign numeric value of 2020
brexit_event = True -create a boolean variable with a true or false value
print(“hello ” + country_name + ” and welcome to the year ” + str(number_of_years) -Note that you can’t concatenate a string and an integer so you need to convert the integer to a string using the str() function
executing the hello.py script comprised of the three lines above
print (“Cyberfella Limited”\n”python tutorial”) -puts a new line between the two strings
print (“Cyberfella\\Limited”) -escape character permits the print of the backslash or other special character that would otherwise cause a syntax error such as a “
phrase = “CYBERFELLA”
print (phrase.lower()) -prints the string phrase in lowercase. There are other functions builtin besides upper and lower to change the case.
print (phrase.islower()) -returns False if the string phrase is not lower case
print (phrase.lower().islower()) -returns True after converting the uppercase string phrase to lowercase.
print (len(phrase)) -returns the length of the string, i.e. 10
print (phrase[0]) -returns the first letter of the string, i.e. C
print (phrase.index(“Y”)) -returns the location of the first matching parameter in the string i.e. 1 Note you can have a string as a parameter e.g. CYB
print (phrase.replace(“FELLA”,”FELLA LTD”)) -replaces matching part of the string (substring) FELLA with FELLA LTD
WORKING WITH NUMBERS
Python can do basic arithmetic as follows, print (2.5 + 3.2 * 5 / 2)
python performing arithmetic 2.5 + 3.2 * 5 / 2 = 10.5 based on the PEMDAS order of operations. The “operations” are addition, subtraction, multiplication, division, exponentiation, and grouping; the “order” of these operations states which operations take precedence (are taken care of) before which other operations. … Multiplication and Division (from left to right) Addition and Subtraction (from left to right)
To change the order of operations, place the higher priority arithmetic in parenthesis, e.g. print (2 * (3 + 2))
3+2 = 5 and 2 * 5 = 10. The addition is prioritised over the multiplication by placing the addition in () to be evaluated first.
print (10 % 3) is called the Modulus function, i.e. 10 mod 3. This will divide 10 by 3 and give the remainder, i.e. 10 / 3 = 3 remainder 1. So it outputs 1.
How to perform a MOD function, i.e. give the remainder when two numbers are divided. e.g. 10 % 3 (10 mod 3) = 1
The absolute value can be obtained using the abs function, e.g. print (abs(my_num))
The variable my_num had been assigned a value of -98
print (pow(3,2)) prints the outcome of 3 to the power of 2, i.e. 3 squared.
3 squared is 9
print (max(4,6)) prints the larger of the two numbers, i.e. 6 min does the opposite
6 is larger than 4
print (round(3.7)) rounds the number, i.e. 4
3.7 rounded is 4
There are many more math functions but they need to be imported from the external math module. This is done by including the line from math import * in your code
print (floor(3.7)) takes the 3 and chops off the 7 (rounds down) ceil does the opposite (rounds up)
The floor function imported from the math module, returns the whole number but not the fraction
print (sqrt(9)) returns the square root of a number, i.e. 3.
the square root of 9 is 3.0 according to pythons sqrt function
GETTING INPUT FROM USERS
name = input (“Enter your name: “) will create a variable name and assign it the value entered by the user when prompted by the input command.
num1 = input (“Enter a number: “)
num2 = input (“Enter another number: “)
Any input from a user is treated as a string, so in order to perform arithmetic functions on it, you need to use int or float to tell python to convert the string to an integer or floating point number if it contains a decimal point.
result = int(num1) + int(num2) or result = float(num1) + float(num2)
print (result)
WORKING WITH LISTS
Multiple values are stored in square brackets, in quotes separated by commas,
friends = [“Eldred”, “Chris”, “Jules”, “Chris”]
You can store strings, numbers and booleans together in a list,
friend = [“Eldred”, 1, True]
Elements in the list start with an index of zero. So Chris would be index 1.
print(friends[1])
Note that print (friends[-1]) would return the value on the other end of the list and print (friends[1:]) will print the value at index 1 and everything after it. print (friends[1:3]) will return element at index 1 and everything after it, up to but not including element at index position 3.
To replace the values in a list,
friends[1] = “Benny” would replace Chris with Benny
USING LIST FUNCTIONS
lucky_numbers = [23, 8, 90, 44, 42, 7, 3]
To extend the list of friends with the values stored in lucky_numbers, effectively joining the two lists together,
friends.extend(lucky_numbers) Note that since Python3 you’d need to use friends.extend(str(lucky_numbers)) to convert the integers to strings before using functions such as sort or you’ll receive an error when attempting to sort a list that is a mix of integers and strings.
To simply add a value to the existing list
friends.append(“Helen”)
To insert a value into a specific index position,
friends.insert(1, “Sandeep”)
To remove a value from the list,
friends.remove(“Benny”)
To clear a list, use friends.clear()
To remove the last element of the list, use friends.pop()
To see if a value exists in the list and to return its index value,
print (friends.index(“Julian”))
To count the number of similar elements in the list,
print (friends.count(“Chris”))
To sort a list into alphabetical order,
friends.sort()
print (friends)
To sort a list of numbers in numerical order,
lucky_numbers.sort()
print (lucky_numbers)
To reverse a list, lucky_numbers.reverse()
Create a copy of a list with,
friends2 = friends.copy()
WORKING WITH TUPLES (pronounced tupples)
A tuple is a type of data structure that stores multiple values but has a few key differences to a list. A tuple is immutable. You can’t change it, erase elements, add elements or any of the above examples of ways you can manipulate a list. Once set, that’s it.
Create a tuple the same way you would a list, only using parenthesis instead of square brackets,
coordinates = (3, 4)
print (coordinates[0]) returns the first element in the tuple, just as it does in a list.
Generally, if python stores data for any reason whereby it doesn’t stand to get manipulated in any way, it’s stored in a tuple, not a list.
FUNCTIONS
Just as with Shell Scripting, a function is a collection of code that can be called from within the script to execute a sequence of commands. function names should be in all lowercase and underscores are optional if you want to see a space in the function name for better readability, e.g. hello_world or helloworld are both acceptable.
def hello_world ():
print (“Hello World!”)
commands inside the function MUST be indented. To call the function from within the program, just use the name of the function followed by parenthesis, e.g.
hello_world()
You can pass in parameters to a function as follows,
def hello_user (name):
print (“Hello ” + name)
pass the name in from the program with hello_user(“Bob”)
def hello_age (name, age):
print (“Hello ” + name = ” you are ” + str(age))
hello_age (“Matt”, 45)
RETURN STATEMENT
In the following example, we’ll create a function to cube a number and return a value
def cube (num);
return (num ^3)
Call it with print (cube(3)). Note that without the return statement, the function would return nothing despite performing the math as instructed.
result = cube(4)
print (result)
Note that in a function that has a return statement, you cannot place any more code after the return statement in that function.
IF STATEMENTS
Firstly, set a Boolean value to a variable,
is_male = True
If statement in python process the first line of code when the boolean value of the variable in the IF statement is True, i.e.
if is_male:
print (“You are a male”)
This would print “You are a male” to the screen, whereas if is_male = False, it’d do nothing.
if is_male:
print (“You are a male”)
else:
print (“You are not a male”)
Now, what about an IF statement that checks multiple boolean variables? e.g.
is_male = True
is_tall = True
if is_male or is_tall:
print “You’re either male or tall or both”
else:
print “You’re neither male nor tall”
an alternative to using or is to use and e.g.
if is_male and is_tall:
print “You are a tall male”
else:
print “You’re either not male or not tall or both”
Finally, by using the elif statement(s) between the if and else statements, we can execute a command or commands in the event that is_male = True but is_tall is False, i.e.
if is_male and is_tall:
print “You are male and tall”
elif is_male and not(is_tall):
print “You are not a tall male”
elif not(is_male) and is_tall:
print “You are tall but not male”
else:
print “You are neither male nor tall”
IF STATEMENTS AND COMPARISONS
The following examples show how you might compare numbers or strings using a function containing if statements and comparison operators.
#Comparison Operators #Function to return the biggest number of three numbers def max_num(num1, num2, num3): if num1 >= num2 and num1 >= num3: return num1 elif num2 >= num1 and num2 >= num3: return num2 else: return num3
print (max_num(3, 4, 5))
#Function to compare three strings def match(str1, str2, str3): if str1 == str2 and str1 == str3: return "All strings match" elif str1 == str2 and str1 != str3: return "Only the first two match" elif str1 != str2 and str2 == str3: return "Only the second two match" elif str1 == str3 and str1 != str2 return "Only the first and last match" else: return "None of them match"
print (match("Bob", "Alice", "Bob"))
python also supports <> as well as != and can also compare strings and numbers e.g. ’12’ <> 12
BUILDING A CALCULATOR
This calculator will be able to perform all basic arithmetic, addition, subtraction, multiplication and division.
#A Calculator num1 = float(input("Enter first number: ")) op = input("Enter operator: ") num2 = float(input("Enter first number: "))
if op == "+": print(num1 + num2) elif op == "-": print(num1 - num2) elif op == "/": print(num1 / num2) elif op == "*": print(num1 * num2) else: print "Invalid operator"
DICTIONARIES
Key and Value pairs can be stored in python dictionaries. To create a dictionary to store say, three letter months and full month names, you’d use the following structure. Note that in a dictionary the keys must be unique.
while guess != secret_word and not out_of_guesses: #will loop code while conditions are True if tries < limit: guess = input("Enter guess: ") tries += 1 else: out_of_guesses = True
if out_of_guesses: #executes if condition/boolean variable is True print ("Out of guesses, you lose!") else: #executes if boolean condition is False print ("You win")
FOR LOOPS
Here are some examples of for loops
#FOR LOOPS
for eachletter in "Cyberfella Ltd":
print (eachletter)
friends = ["Bob", "Alice", "Matt"]
for eachfriend in friends:
print(eachfriend)
for index in range(10):
print(index) #prints all numbers starting at 0 excluding 10
for index in range(3,10):
print(index) #prints all numbers between 3 and 9 but not 10
for index in range (len(friends)):
print(friends[index]) #prints out all friends at position 0, 1, 2 etc depending on the length of the list or tuple of friends
for index in range (5):
if index == 0:
print ("first iteration of loop")
else:
print ("not first iteration")
EXPONENT FUNCTIONS
print (2**3) #prints 2 to the power of 3
Create a function called raise_to_power to take a number and multiply it by itself a number of times,
def raise_to_power(base_num, pow_num): result = 1 for index in range (pow_num): #carry on multiplying the number by itself until you hit the range limit specified by pow_num result = result * base_num return result
2D LISTS AND NESTED LOOPS
In python, you can store values in a table, or 2D list, and print the values from certain parts of the table depending on their row and column positions. note that positions start at zero, not 1.
#Create a grid of numbers, that is 4 rows and 3 columns number_grid = [ [1,2,3], [4,5,6], [7,8,9], [0] ] #return the value from first row (row 0) first column (position 0) print number_grid [0][0] #returns 1
#return the value from third row (row 2) third column (position 2) print number_grid [0][0] #returns 9
for eachrow in number_grid: print (row)
for eachrow in number_grid: for column in eachrow: print (column) #returns the value of each column in each row until it hits the end
BUILD A TRANSLATOR
This little program is an example of nested if statements that take user input and translate any vowels in the string input to an upper or lowercase x
#CONVERTS ANY VOWELS TO A X def translate(phrase): translation = "" for letter in phrase: if letter.lower() in "aeiou": if letter.isupper(): translation = translation + "X" else translation = translation + "x" else: translation = translation + letter return translation
print(translate(input("Enter a phrase: ")))
TRY EXCEPT
Catching errors in your program to prevent the program from being prevented from running. Error handling in python for example, if you prompt the user for numerical input and they provide alphanumerical input, the program would error and stop.
number = int(input(“Enter a number: “))
The variable number is set based upon the numerical, or more specifically the integer value of the users input. In order to handle all the potential pitfalls, we can create a “try except” block, whereby the code that could “go wrong” is indented after a try: and the code to execute in the event of an error, being indented after the except: block, e.g.
try: number = int(input("Enter a number: ")) print(number) except: print("Invalid input, that number's not an integer")
Specific error types can be caught by specifying the type of error after except. Using an editor like pycharm will display the possible options or errors that can be caught but the specific error will be in the output of the script with it stops.
So if we execute the code outside of a try: block, and enter a letter when asked for an integer, we’d get the following error output that we can then use to create our try: except: block to handle that specific ValueError error type in future.
You can add multiple except: blocks in a try: except: block of code.
If you want to capture a certain type of error and then just display that error, rather than a custom message or execute some alternative code then you can do this…
This can be useful during troubleshooting.
READING FROM FILES
You can “open” a file in different modes, read “r”, write “w”, append “a”, read and write “r+”
employee_file = open(“employees.txt”, “r”) #Opens a file named employees.txt in read mode
It’s worth checking that the file can be read, print(employee_file.readable())
You need to close the file once you’re done with it,
employee_file.close()
The examples below show different ways you can read from a file
#READING FROM FILES
employee_file = open("employees.txt", "r") #opens file read mode
print(employee_file.readable()) #checks file is readable
print(employee_file.read()) #reads entire file to screen
print(employee_file.readline()) #can be used multiple times to read next line in file
print(employee_file.readlines()) #reads each line into a list
print(employee_file.readlines()[1]) #reads into a list and displays item at position 1 in the list
employee_file.close() #closes file
for employee in employee_file.readlines():
print (employee)
employee_file.close()
WRITING AND APPENDING TO FILES
You can append a a file by opening it in append mode, or overwrite/write a new file by opening it in write mode. You may need to add newline characters in append mode to avoid appending your new line onto the end of the existing last line.
#WRITING AND APPENDING TO FILE employee_file = open("employees.txt", "a") #opens file append mode employee_file.write("Toby - HR") #in append mode will append this onto the end of the last line, not after the last line employee_file.write("\nToby - HR") #in append mode will add a newline char to the end of the last line, then write a new line
employee_file = open("employees.txt", "w") #opens file write mode employee_file.write("Toby - HR") #in write mode, this will overwrite the file entirely
employee_file.close()
MODULES AND PIP
Besides the builtin modules in python, python comes with some additional modules that can be read in by your python code to increase the functionality available to you. This can reduce time since many things you may want to achieve have already been written in one of these modules. This is really what python is all about – the ability to pull in the modules you need, keep everything light and reduce time.
IMPORTING FUNCTIONS FROM EXTERNAL FILES
import useful_tools
print(useful_tools.roll_dice(10))
# MORE MODULES AT docs.python.org/3/py-modindex.html
SOME USEFUL COMMANDS
feet_in_mile = 5280
metres_in_kilometer = 1000
beatles=["John", "Ringo", "Paul", "George"]
def get_file_ext(filename):
return filename[filename.index(".") + 1:]
def roll_dice(num):
return random.randint(1, num)
To use a module in an external file, use print(useful_tools.roll_dice(10)) for example (rolls a 10 sided dice).
EXTERNAL MODULES
Besides the additional internal modules that can be read into your python script, there are also many external modules maintained by a huge community of python programmers. Many of these external modules can be installed using the builtin pip command that comes as part of python. e.g. pip install python-docx will install the external python module that allows you to read and write to Microsoft Word documents.
You can install pip using your package manager
To uninstall a python modules, use pip uninstall python-docx for example.
CLASSES AND OBJECTS
A class defines a datatype. In the example, we create a datatype or class for a Student.
class Student: def __init__(self, name, major, gpa, is_on_probation): self.name = name self.major = major self.gpa = gpa self.is_on_probation = is_on_probation
This can be saved in its own class file called Student.py and can be imported into your python script using the command from Student import Student i.e. from the Student file, I want to import the Student class.
To create an object that is an instance of a class, or in our case, a student that is an instance of the Student class, we can use student1 = Student(“Bob”, “IT”, 3.7, False)
print (student1.name) will print the name attribute of the student1 object.
BUILDING A MULTIPLE CHOICE QUIZ
If you’re using pycharm to create your python code, then Click File, New, Python File and create an external class named Question.py. This will define the data type for the questions in your main multiple choice quiz code.
Now in your main code, read in that Questions.py class, create some questions in a list called question_prompts, and define the answers to those questions in another list called questions, e.g.
from Question import Question
question_prompts = [
"What colour are apples?\n(a) Red/Green\n(b) Purple\n(c) Orange\n\n",
"What colour are Bananas\n(a) Teal\n(b) Magenta\n(c) Yellow\n\n",
"What colour are Strawberries?\n(a) Yellow\n(b) Red\n(c) Blue\n\n"
]
questions = [
Question(question_prompts[0], "a"),
Question(question_prompts[1], "c"),
Question(question_prompts[2], "b"),
]
Now create a function to ask the questions, e.g.
def run_test(questions): score = 0 for question in questions: answer = input(question.prompt) if answer == question.answer: score +=1 print("You got " + str(score) + "/" + str(len(questions)) + " correct")
and lastly, create one line of code in the main section that runs the test.
run_test (questions)
OBJECT FUNCTIONS
Consider the following scenario – a python class that defines a Student data type, i.e.
class Student: def __init__(selfself, name, major, gpa): self.name = name self.major = major self.gpa = gpa
An object function is a function that exists within a class. In this example, we’ll add a function that determines if the student is on the honours list, based upon their gpa being above 3.5
In the Student.py class, we’ll add a on_honours_list function
class Student:
def __init__(self, name, major, gpa):
self.name = name
self.major = major
self.gpa = gpa
def on_honours_list(self):
if self.gpa >= 3.5:
return True
else:
return False
and in our app, we’ll add a line of code to check if a particular student is on the honours list.
Classes can inherit the functions from other classes, this is done as follows. Consider a class that defines a Chef object, e.g.
class Chef:
def make_chicken(self): print("The chef makes a chicken")
def make_salad(self): print("The chef makes a salad")
def make_special_dish(self): print("The chef makes bbq ribs")
Within the main app code, you can instruct the Chef as follows.
from Chef import Chef
myChef = Chef()
myChef.make_chicken()
myChef.make_special_dish()
But what if there was a Chinese Chef who could do everything that the Chef could do, but also made additional dishes and a different special dish? Creating an additional class for the ChineseChef as follows would facilitate this. e.g. ChineseChef.py would contain…
from Chef import Chef class ChineseChef(Chef): def make_special_dish(self): print ("The chef makes Orange Chicken")
def make_fried_rice(self): print ("The chef makes fried rice")
So, the class imports the other class, then the skills unique to the Chinese Chef are added, and also, any of the same skills overridden by re-defining them within the ChineseChef class.
PYTHON INTERPRETER
On Windows, Mac or Linux, you can access the python command line interpreter to perform some quick and dirty tests of your commands, Note that python is very particular about it’s tab indented code where applicable – something that was done in say Shell Scripting at the discretion of the programmer for ease of readability – python really enforces it. e.g.
Using the python command will likely open an interpreter for python v2.x whereas the python3 command will open the interpreter for python v3.x. Be sure to add the path to the PATH environment variable if using Windows.
For coding in python, it’s best to use a good text editor, Notepad++ (notepadqq on linux), or a proper coding text editor such as Visual Studio Code (runs on linux as well as Windows and Mac) or Atom or the best dedicated to writing python in particular is PyCharm. The community edition is free, or there is a paid for, Professional Edition.
I found PyCharm be be available via my Software Manager on Linux Mint.
Did you like this? Tip cyberfella with Cryptocurrency
DevOps is the key to Continuous Delivery. How is this achieved? First it is useful to consider the evolution of the previous models of project management, namely Waterfall and Agile.
AGILE
Agile addressed the gap between client requirements and development, but a disconnect remained between the developers and the operations teams, i.e. applications were being developed on different systems to the ones they would ultimately be deployed upon with the assumption that the production infrastrcuture was bigger and more powerful than the development laptop so it would all be fine.
DevOps is a logical evolution of the Agile shift and addresses the link between developers and operations so that continuous delivery and continuous integration can be achieved along with the promise of fast product to market times and quicker return of value to the client. This utopia is further realised since much infrastructure is now hosted in the cloud and is in itself code (infrastructure as code). This doesn’t so much bring the operations and dev teams closer together as blur the divide between them, since they now use many common tools.
It also facilitates a feedback loop rather than a left-to-right delivery paradigm.
The figure of 8 diagram above shows the sequence of phases in a DevOps environment that facilitate continuous delivery, continuous integration and continous deployment. More on what that means below… First lets have a quick look at each of the phases shown in the diagram, starting with the Planning Phase.
It’s worth noting at this point that many open-source tools are used in each stage of the DevOps process. We’ll cover some of the more commonly used tools as we go along.
It is also worth noting that many of these tools are designed to automate the functions of a build engineer, tester or operator.
PLAN
To sit down with business teams and understand their goals. Tools used in this phase are Subversion and IntelliJIDEA.
CODE
Programmers design code using git to carefully control versioning and branches of code that may be a collaborative effort, ultimately merging the branches into a new build. More on the elementary use of githere. Code may be shell script, python, powershell or any other language and git can maintain version control of developers local repositories of code and the projects main private and public repositories held online at github that collaborating devs keep in sync with.
BUILD
Build tools such as Maven and Gradle take code from different repositories and combine them to build the complete application.
TEST
Testing of code is automated using tools such as Selenium, JUnit to ensure software quality. The testing environment is scripted just as the build environment is.
INTEGRATE
Jenkins integrates new features once testing is complete, to the already existing codebase. Another tool used in the integration phase is Bamboo.
DEPLOY
BMC XebiaLabs can be used to package the application after Jenkins release and is deployed from the Developement Server to the Production Server.
OPERATE
Operations elements such as Servers, VM’s and Containers are deployed using tools such as Puppet, Chef and their configuration managed and maintained using tools such as Ansible and Docker. Like the application hosted on the platform, these tools are used to execute code in the cloud and that code can be maintained using git etc just the same as application code for a consistent, self-healing deployment where the scale of the application may require many identically configured elements to host an application that could also be subjected to attacks.
MONITOR
Monitoring frameworks such as Nagios are used to schedule scripted checks of parts of the solution and the consequences of the results collated by Groundwork and/or Splunk>. A nagios monitoring script should exit with a status of 0, 1 or 2 (OK, Error, Warning) and may be displayed on a board for operators to see, but may also feed back into the development cycle automatically.
So, all these tools, all this code and the utopia of entirely automated, cloud infrastructure is often described as Continuous Integration/ Continuous Delivery/Continous Deployment or “CI/CD” for short. Lets make the distinction between the three…
CONTINUOUS DELIVERY
This is effectively the outcome of the PLAN, CODE, BUILD and TEST phases.
CD = PLAN <–> CODE <–> BUILD <–> TEST
CONTINUOUS INTEGRATION
This is effectively the outcome of the CD phases above plus the outcome of the RELEASE phase, i.e.
CI = CD <–> RELEASE
or
CI = PLAN <–> CODE <–> BUILD <–> TEST <–> RELEASE
whereby the outcome of the RELEASE phase (defect or success) is fed back into the Continuous Delivery phases above or moved into the DEPLOY, OPERATE and MONITOR phases or “Continuous Deployment” phases respectively, i.e.
CONTINUOUS DEPLOYMENT
“success” outcome from CI –> DEPLOY <–> OPERATE <–> MONITOR
So in summary, the terms Continuous Delivery, Continous Integration and Continuous Deployment is simply a collective term for multiple phases of the DevOps cycle…
COMPARISON WITH WATERFALL and AGILE
Waterfall projects can take weeks, months or years before the first deployment of a working product, only to find bugs when released into the wild on a much larger user base than the developers and testing teams. This is an extremely stressful time if you’re the dev tasked with finding and fixing the root cause of the bugs in the days after go-live, especially when the production system is separate in every sense of the word from the developers working environment, not to mention the potential for poor public image, poor customer PR and spiralling costs after heavy upfront costs.
REQUIREMENTS ANALYSIS –> DESIGN –> DEVELOPMENT –> TESTING –> MAINTENANCE
Agile projects use kanban boards to monitor tasks in the Pending, Active, Complete and Resolved columns. Agreed Sprints lasting 2 weeks or 4 weeks (sprint cadence) ultimately resulting in a new release, drives value back to the customer in a guaranteed schedule, with outstanding tasks and bugs still being worked on during the next sprint.
SPRINT = [ PLAN <–> CODE <–> TEST <–> REVIEW ] + SCRUM
DevOps in comparison, heavily leverages automation and a diverse toolset to bring the sprint cadence down to days or even a daily release.
-> PLAN <–> CODE <–> BUILD <–> TEST <–> INTEGRATE <–> DEPLOY <–> OPERATE <–> MONITOR<-
ADVANTAGES OF DEVOPS
As an example, Netflix accounts for a third of all network traffic on the internet, yet it’s DevOps team is just 70 people.
The time taken to create and deliver software is greatly reduced.
The complexity of maintaining an application is reduced via automation and scripting.
Teams aren’t silo’d according to discrete skill sets. They work cohesively at various phases in the loop, their roles assigned during daily scrums.
Value is delivered more readily to the customer and up-front costs reduced.
Did you like this? Tip cyberfella with Cryptocurrency
Distributed Version Control System (VCS) for any type of file
Co-ordinates work between multiple developers
Tracks who made what changes and when
Revert back at any time
Supports local and remote repositories (hosted on github, bitbucket)
It keeps track of code history and takes snapshots of your files You decide when to take a snapshot by making a commit You can visit any snapshot at any time You can stage files before committing
INSTALLING git sudo apt-get install git (debian) sudo yum install git (red hat) https://git.scm.com (installers for mac and windows) gitbash is a linux-like command cli for windows
CONFIGURING git git config –global user.name ‘matt bradley’ git config –global user.email ‘matt@cyberfella.co.uk’ touch .gitignore echo “log.txt” >> .gitignore Add file to be ignored by git, e.g. log file generated by script echo “/log” >> .gitignore Add directory to be ignored, e.g. log directory
BASIC COMMANDS (local repository) git init Initialize a local git repository (creates a hidden .git subdirectory in the directory) git add Adds file(s) to Index and Staging area ready for commit. git add . Adds all files in directory to Staging area git status check status of working tree, show files in Staging area and any untracked files you still need to add git commit commit changes in index – takes files in staging are and puts them in local repository git commit -m ‘my comment’ Skips git editing stage adding comment from command. git rm –cached removes from staging area (untracked/unstaged).
BASIC COMMANDS (remote repo) git push push files to remote repository git pull pull latest version from remote repo git clone clone repo into a local directory
git clone https://github.com/cyberfella/cyberfella.git clones my cyberfella repository
git –version shows version of git installed
BRANCHES git branch loginarea creates a branch from master called “loginarea” git checkout loginarea switches to the “loginarea” branch git checkout master switches back to the master branch version git merge ‘loginarea’ merges changes made to ‘loginarea’ files in loginarea branch to master branch
REMOTE REPOSITORY https://github.com/new Create a public or private repository Shows the commands required to create a new repository on the command line or push an existing repository from the command line
README.md A readme.md (markdown format) file displays nicely in github.
In short, Relax and Recover (rear) is a tool that creates .tar.gz images of the running server and creates bootable rescue media as .iso images
Relax and Recover (ReaR) generates an appropriate rescue image from a running system and also acts as a migration tool for Physical to Virtual or Virtual to Virtual migrations of running linux hosts.
It is not per se, a file level backup tool. It is akin to Clonezilla – another popular bare metal backup tool also used to migrate Linux into virtual environments.
There are two main commands, rear mkbackuponly and rear mkrescue to create the backup archive and the bootable image respectively. They can be combined in the single command rear mkbackup.
The bootable iso provides a configured bootable rescue environment that, provided your backup is configured correctly in /etc/rear/local.conf, will make recovery as simple as typing rear recover from the recovery prompt.
You can back up to NFS or CIFS Share or to a USB block storage device pre-formatted by running rear format /dev/sdX
A LITTLE MORE DETAIL
A professional recovery system is much more than a simple backup tool.
Experienced admins know they must control and test the entire workflow for the recovery process in advance, so they are certain all the pieces will fall into place in case of an emergency.
Versatile replacement hardware must be readily available, and you might not have the luxury of using a replacement system that exactly matches the original.
The partition layout or the configuration of a RAID system must correspond.
If the crashed system’s patch level was not up to date, or if the system contained an abundance of manually installed software, problems are likely to occur with drivers, configuration settings, and other compatibility issues.
Relax and Recover (ReaR) is a true disaster recovery solution that creates recovery media from a running Linux system.
If a hardware component fails, an administrator can boot the standby system with the ReaR rescue media and put the system back to its previous state.
ReaR preserves the partitioning and formatting of the hard disk, the restoration of all data, and the boot loader configuration.
ReaR is well suited as a migration tool, because the restoration does not have to take place on the same hardware as the original.
ReaR builds the rescue medium with all existing drivers, and the restored system adjusts automatically to the changed hardware.
ReaR even detects changed network cards, as well as different storage scenarios with their respective drivers (migrating IDE to SATA or SATA to CCISS) and modified disk layouts.
The ReaR documentation provides a number of mapping files and examples.
An initial full backup of the protected system is the foundation.
ReaR works in collaboration with many backup solutions, including Bacula/Bareos SEP SESAM, Tivoli Storage Manager, HP Data Protector, Symantec NetBackup, CommVault Galaxy, and EMC Legato/Networker.
WORKING EXAMPLE
Below is a working example of rear in action, performed on fresh Centos VM’s running on VirtualBox in my own lab environment.
Note: This example uses a Centos 7 server and a NFS Server on the same network subnet.
START A BACKUP
On the CentOS machine
Add the following lines to /etc/rear/local.conf:
OUTPUT=iso
BACKUP=NETFS
BACKUP_TYPE=incremental
BACKUP_PROG=tar
FULLBACKUPDAY=”Mon”
BACKUP_URL=”nfs://NFSSERVER/path/to/nfs/export/servername”
BACKUP_PROG_COMPRESS_OPTIONS=”–gzip”
BACKUP_PROG_COMPRESS_SUFFIX=”.gz”
BACKUP_PROG_EXCLUDE=( ‘/tmp/*’ ‘/dev/shm/*’ )
BACKUP_OPTIONS=”nfsvers=3,nolock”
Now make a backup
[root@centos7 ~]# rear mkbackup -v
Relax-and-Recover 1.16.1 / Git
Using log file: /var/log/rear/rear-centos7.log
mkdir: created directory ‘/var/lib/rear/output’
Creating disk layout
Creating root filesystem layout
TIP: To login as root via ssh you need to set up /root/.ssh/authorized_keys or SSH_ROOT_PASSWORD in your configuration file
Copying files and directories
Copying binaries and libraries
Copying kernel modules
Creating initramfs
Making ISO image
Wrote ISO image: /var/lib/rear/output/rear-centos7.iso (90M)
Copying resulting files to nfs location
Encrypting disabled
Creating tar archive ‘/tmp/rear.QnDt1Ehk25Vqurp/outputfs/centos7/2014-08-21-1548-F.tar.gz’
Archived 406 MiB [avg 3753 KiB/sec]OK
Archived 406 MiB in 112 seconds [avg 3720 KiB/sec]
Now look on your NFS server
You’ll see all the files you’ll need to perform the disaster recovery.
total 499M
drwxr-x— 2 root root 4.0K Aug 21 23:51 .
drwxr-xr-x 3 root root 4.0K Aug 21 23:48 ..
-rw——- 1 root root 407M Aug 21 23:51 2014-08-21-1548-F.tar.gz
-rw——- 1 root root 2.2M Aug 21 23:51 backup.log
-rw——- 1 root root 202 Aug 21 23:49 README
-rw——- 1 root root 90M Aug 21 23:49 rear-centos7.iso
-rw——- 1 root root 161K Aug 21 23:49 rear.log
-rw——- 1 root root 0 Aug 21 23:51 selinux.autorelabel
-rw——- 1 root root 277 Aug 21 23:49 VERSION
INCREMENTAL BACKUPS
ReaR is not a file level Recovery tool (Look at fwbackups) however, you can perform incremental backups, in fact, in the “BACKUP_TYPE=incremental” parameter which takes care of that.
As you can see from the file list above, it shows the letter “F” before the .tar.gz extension which is an indication that this is a full backup.
Actually it’s better to make the rescue ISO seperately from the backup.
The command “rear mkbackup -v” makes both the bootstrap ISO and the backup itself, but running “rear mkbackup -v” twice won’t create incremental backups for some reason.
So first:
[root@centos7 ~]# time rear mkrescue -v
Relax-and-Recover 1.16.1 / Git
Using log file: /var/log/rear/rear-centos7.log
Creating disk layout
Creating root filesystem layout
TIP: To login as root via ssh you need to set up /root/.ssh/authorized_keys or SSH_ROOT_PASSWORD in your configuration file
Copying files and directories
Copying binaries and libraries
Copying kernel modules
Creating initramfs
Making ISO image
Wrote ISO image: /var/lib/rear/output/rear-centos7.iso (90M)
Copying resulting files to nfs location
real 0m49.055s
user 0m15.669s
sys 0m10.043s
And then:
[root@centos7 ~]# time rear mkbackuponly -v
Relax-and-Recover 1.16.1 / Git
Using log file: /var/log/rear/rear-centos7.log
Creating disk layout
Encrypting disabled
Creating tar archive ‘/tmp/rear.fXJJ3VYpHJa9Za9/outputfs/centos7/2014-08-21-1605-F.tar.gz’
Archived 406 MiB [avg 4166 KiB/sec]OK
Archived 406 MiB in 101 seconds [avg 4125 KiB/sec]
real 1m44.455s
user 0m56.089s
sys 0m16.967s
Run again (for incrementals)
[root@centos7 ~]# time rear mkbackuponly -v
Relax-and-Recover 1.16.1 / Git
Using log file: /var/log/rear/rear-centos7.log
Creating disk layout
Encrypting disabled
Creating tar archive ‘/tmp/rear.Tk9tiafmLyTvKFm/outputfs/centos7/2014-08-21-1608-I.tar.gz’
Archived 85 MiB [avg 2085 KiB/sec]OK
Archived 85 MiB in 43 seconds [avg 2036 KiB/sec]
real 0m49.106s
user 0m10.852s
sys 0m3.822s
Now look again at those backup files: -F.tar.gz is the Full Backup, -I.tar.gz is the Incremental. There’s also basebackup.txt and timestamp.txt files.
total 585M
drwxr-x— 2 root root 4.0K Aug 22 00:09 .
drwxr-xr-x 3 root root 4.0K Aug 22 00:04 ..
-rw-r–r– 1 root root 407M Aug 22 00:07 2014-08-21-1605-F.tar.gz
-rw-r–r– 1 root root 86M Aug 22 00:09 2014-08-21-1608-I.tar.gz
-rw-r–r– 1 root root 2.6M Aug 22 00:09 backup.log
-rw-r–r– 1 root root 25 Aug 22 00:05 basebackup.txt
-rw——- 1 root root 202 Aug 22 00:05 README
-rw——- 1 root root 90M Aug 22 00:05 rear-centos7.iso
-rw——- 1 root root 161K Aug 22 00:05 rear.log
-rw-r–r– 1 root root 0 Aug 22 00:09 selinux.autorelabel
-rw-r–r– 1 root root 11 Aug 22 00:05 timestamp.txt
-rw——- 1 root root 277 Aug 22 00:05 VERSION
RECOVERY
ReaR is designed to create bootable .iso, making recovery very easy and flexible in terms of options. .iso files can be booted from CD/DVD optical media, USB Block Storage Devices & Hard disks and also in VMWare & Virtual Box.
To recover a system, you first need to boot to the .ISO that was created with the backup.
You may use your favorite method for booting to the .ISO whether it’s creating a bootable USB sick, burning it to a CD, mounting it in iDRAC, etc.
Just boot to it on the server in which you want to restore to.
When the recovery screen loads, select the top option to recover.
Type root to log in.
To start recovery, type rear -v recover
# Navigate to and list files in /var/lib/rear/layout/xfs
# Edit each file ending in .xfs with vi and remove “sunit=0 blks” from the “log” section.
# In my case, the following files, then save them: vi /var/lib/rear/layout/xfs/fedora_serv–build-root.xfs vi /var/lib/rear/layout/xfs/sda1.xfs vi /var/lib/rear/layout/xfs/sdb2.xfs
# Run the following commands to get a list of LVs and VGs: lvdisplay vgdisplay
# Run the following commands to remove the above listed LVs and VGs: lvremove vgremove
Unlike VMWare/Virtualbox virtualisation, containers wraps up individual workloads (instead of the entire OS and kernel) and their dependencies into relatively tiny containers (or “jails” if youre talking FreeNAS/AIX, or “zones” if you’re talking Solaris, “snaps” if you’re talking Ubuntu Core). There are many solutions to linux containerisation in the marketplace at present, and LXC is free.
This post serves as a go-to reference page for examples of all the most commonly used lxc commands when dealing with linux containers. I highly recommend completing all the sections below, running all the commands on the test server available at linuxcontainers.org, to fully appreciate the context of what you are doing. This post is a work in progress and will likely be augmented over time with examples from my own lab, time permitting.
Your first container
LXD is image based, however by default no images are loaded into the image store as can be seen with:
lxc image list
LXD knows about 3 default image servers:
ubuntu: (for Ubuntu stable images)
ubuntu-daily: (for Ubuntu daily images)
images: (for a bunch of other distributions)
The stable Ubuntu images can be listed with:
lxc image list ubuntu: | less
To launch a first container called “first” using the Ubuntu 16.04 image, use:
lxc launch ubuntu:16.04 first
Your new container will now be visible in:
lxc list
Running state details and configuration can be queried with:
lxc info first lxc config show first
Limiting resources
By default your container comes with no resource limitation and inherits from its parent environment. You can confirm it with:
free -m lxc exec first — free -m
To apply a memory limit to your container, do:
lxc config set first limits.memory 128MB
And confirm that it’s been applied with:
lxc exec first — free -m
Snapshots
LXD supports snapshoting and restoring container snapshots.
Before making a snapshot, lets do some changes to the container, for example, updating it:
lxc exec first — apt-get update lxc exec first — apt-get dist-upgrade -y lxc exec first — apt-get autoremove –purge -y
Now that the container is all updated and cleaned, let’s make a snapshot called “clean”:
lxc snapshot first clean
Let’s break our container:
lxc exec first — rm -Rf /etc /usr
Confirm the breakage with (then exit):
lxc exec first — bash
And restore everything to the snapshotted state: (be sure to execute these from the container host, not from inside the container or it won’t work.
lxc restore first clean
And confirm everything’s back to normal (then exit):
lxc exec first — bash
Creating images
As your probably noticed earlier, LXD is image based, that is, all containers must be created from either a copy of an existing container or from an image.
You can create new images from an existing container or a container snapshot.
To publish our “clean” snapshot from earlier as a new image with a user friendly alias of “clean-ubuntu”, run:
lxc publish first/clean –alias clean-ubuntu
At which point we won’t need our “first” container, so just delete it with:
lxc stop first lxc delete first
And lastly we can start a new container from our image with:
lxc launch clean-ubuntu second
Accessing files from the container
To pull a file from the container you can use the “lxc file pull” command:
lxc file pull second/etc/hosts .
Let’s add an entry to it:
echo “1.2.3.4 my-example” >> hosts
And push it back where it came from:
lxc file push hosts second/etc/hosts
You can also use this mechanism to access log files:
lxc file pull second/var/log/syslog – | less
We won’t be needing that container anymore, so stop and delete it with:
lxc delete –force second
Use a remote image server
The lxc client tool supports multiple “remotes”, those remotes can be read-only image servers or other LXD hosts.
LXC upstream runs one such server at https://images.linuxcontainers.org which serves a set of automatically generated images for various Linux distributions.
It comes pre-added with default LXD but you can remove it or change it if you don’t want it.
You can list the available images with:
lxc image list images: | less
And spawn a new Centos 7 container with:
lxc launch images:centos/7 third
Confirm it’s indeed Centos 7 with:
lxc exec third — cat /etc/redhat-release
And delete it:
lxc delete -f third
The list of all configured remotes can be obtained with:
lxc remote list
Interact with remote LXD servers
For this step, you’ll need a second demo session, so open a new one here
Copy/paste the “lxc remote add” command from the top of the page of that new session into the shell of your old session.
Then confirm the server fingerprint for the remote server.
Note that it may take a few seconds for the new LXD daemon to listen to the network, just retry the command until it answers.
At this point you can list the remote containers with:
lxc list tryit:
And its images with:
lxc image list tryit:
Now, let’s start a new container on the remote LXD using the local image we created earlier.
lxc launch clean-ubuntu tryit:fourth
You now have a container called “fourth” running on the remote host “tryit”. You can spawn a shell inside it with (then exit):
lxc exec tryit:fourth bash
Now let’s copy that container into a new one called “fifth”:
lxc copy tryit:fourth tryit:fifth
And just for fun, move it back to our local lxd while renaming it to “sixth”: